


Do you know how much trackers know about you?
Analyzing web tracking from the users’ perspective
Web tracking is ubiquitous on the internet and is performed by websites and organizations to monitor users’ online behavior, learn which pages they visit, understand their preferences, and infer their personal details.
A few reasons behind this practice include providing users with personalized online experiences, and monetizing user-specific information through targeted advertisements.
Consequently, the number of websites that perform tracking is increasing, while the ever-expanding amount of information that trackers collect about users allows them to build more powerful and fine-grained profiles that can help them target users in a more accurate way.
In this complicated tracking landscape, it is hard for consumers to understand how much information tracking organizations know about them. Which portion of the user’s browsing history and sensitive information is known to trackers? How many tracking entities do users encounter and how frequently?
In a recent research study conducted by Norton Labs, we seek to answer those questions by analyzing (anonymized) browsing histories of more than a quarter of a million users. The complete results of our study will be presented at the 31st USENIX Security Symposium in August 2022.
How many and how quickly do users encounter trackers?
We use our telemetry to measure how many different tracking organizations are encountered in one week, and estimate that a single user encounters on average 177 of them. However, users find half of those just in the first two hours of browsing. This suggests that even if the user would restart with a clean browsing history every day, it would only take two hours on average to re-encounter 50% of all trackers. Moreover, those who are active for more consecutive hours tend to be observed by a wider variety of trackers.
For instance, we can consider two users that both have three hours of activity over a 24-hour window. The first browses the internet in three separate sessions of one hour each – morning, afternoon, and evening. The second browses for three hours straight in a single session. In our experiments, we noticed that the second user is more likely to encounter a higher number of unique trackers. The reason is that sessions that are far apart in time are more likely to have larger overlap in the websites visited. In other words, the likelihood of revisiting the same websites and running into already encountered trackers is higher in such cases. On the contrary, users characterized by longer browsing sessions show higher variability in the websites visited and trackers encountered.
How much knowledge do trackers have?
We then analyze which percentage of users’ browsing history is known to trackers. We find that major organizations have broad visibility into users’ browsing behavior. On average, Google, Facebook, and Microsoft, respectively, know 63%, 30%, and 23% of websites in a user’s history.
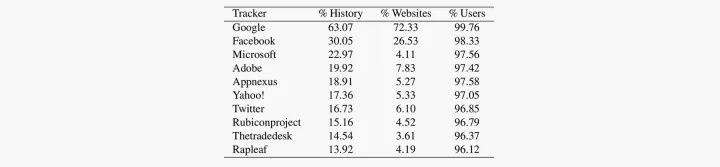
However, these figures only reflect sites where we were able to directly observe the presence of the organizations’ trackers: In fact, it has been shown that trackers share information among each other behind the scenes. In our work, we also estimate how much additional knowledge organizations can gain if they cooperate, from an increase of at least 5% if two organizations cooperate up to more than 50% with broader sharing of data.
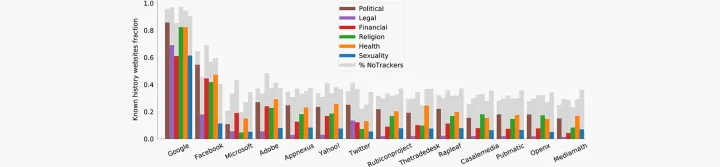
Browsing to certain websites can reveal more personal information about a user than browsing to others. So, our research also studies how much visibility trackers have into websites in several sensitive categories (Political, Legal, Financial, Religion, Health and Sexuality) that could reveal personal information about users. We find that tracking activity is not uniform across sensitive categories.
For instance, sites in the Political category host more trackers than a typical site, and sites in the Legal category host fewer. For most tracking organizations, their visibility into users’ visits to websites in the different sensitive categories follows the same broad trends. Google and Facebook are the exceptions, having more visibility into certain sensitive categories than would be expected from their overall browsing history visibility.
For example, the case of Facebook is particularly remarkable. On the general data, it only knows 30% of users’ browsing history, which is in line with other top players. Despite that, it covers almost 60% of browsing in the Political category, and around 50% in the Health category. This seems to indicate that Facebook puts particular effort into tracking specific website categories. On the other side of the spectrum lies Microsoft, which has much higher visibility into overall browsing history (more than 20%) than it does into users’ browsing in sensitive categories.
What can you do now?
Most current market solutions offering anti-tracking protection normally act as network interceptors, blocking access to domains known to be used for tracking. Unfortunately, sometimes a domain is used both for tracking and also for important non-tracking functionality such as localized content distribution and social network integration.
Preventing tracking by these domains while still allowing them to provide useful functionality requires context. Blindly blocking connections to a list of tracking domains, as many products do, results in broken websites and unhappy users. Alternatively, removing certain domains from the block list in order to improve user experience can result in increased tracking, because any tracking activities from the removed domain are now allowed to proceed unimpeded.
We believe the alternative is to offer a more sophisticated solution capable of performing fine-grained analysis and restricting access to trackers on a granular, case-by-case basis. Technology and innovation prototypes developed by Norton Labs can help consumers stay safe and protect their online privacy while maintaining website functionality. Check our new product: Norton AntiTrack.
Editorial note: Our articles provide educational information for you. NortonLifeLock offerings may not cover or protect against every type of crime, fraud, or threat we write about. Our goal is to increase awareness about cyber safety. Please review complete Terms during enrollment or setup. Remember that no one can prevent all identity theft or cybercrime, and that LifeLock does not monitor all transactions at all businesses.
Copyright © 2021 NortonLifeLock Inc. All rights reserved. NortonLifeLock, the NortonLifeLock Logo, the Checkmark Logo, Norton, LifeLock, and the LockMan Logo are trademarks or registered trademarks of NortonLifeLock Inc. or its affiliates in the United States and other countries. Other names may be trademarks of their respective owners.






We encourage you to share your thoughts on your favorite social platform.