

Striving for Private and Robust Federated Learning
Harnessing the Power of Big Data While Preserving User Privacy
We envision a scenario where a doctor can train a machine learning model capable of developing new cancer treatments but giving control of the most sensitive data to users who own it, not a central entity who you may or may not trust. In traditional cloud-based machine learning (ML) systems, it would require that users move their data (images/text/medical data), hosted on their device, into a single location so that the ML algorithms could “learn” statistical knowledge about that data and embed those learnings into a model that can then predict something about new data when it arrives. This process exposes the user to risks since the service provider can access the users' data, which the service provider can use for other reasons without consent or that data could be accessed by unauthorized people such as a hacker. With this new technique, the patient’s data is not sent to a central location, rather it is analyzed locally and privately. Only the resulting “learning”, not the actual data, is transmitted to the central location and combined with all the other “learnings”, thus keeping the user data private while enabling a doctor to help others with inferences made by the accumulated data.
Federated Learning (FL), originally proposed as a privacy-preserving distributed machine learning technology by Google in 2015 [1], can help address some privacy concerns by allowing each user's device to train the model locally with its own data (see Figure 1). In each iteration of Federated Learning, the users return the local update of the model parameters to the central machine. The central machine takes the average of the local model updates from all the users and shares with the local users the average model parameters for the next iteration of computing (as seen in Figure.1). In this process, a user’s data never leaves their device. These changes in the training phase strengthen the barrier for protecting users' privacy-sensitive information.
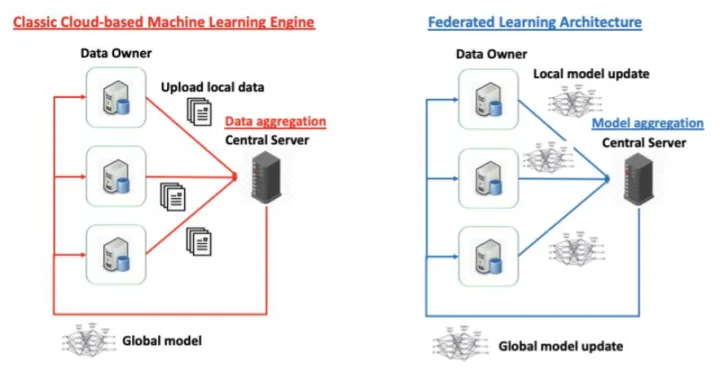
Nevertheless, there are two challenging issues before we can apply Federated Learning widely in practices of data analytical services:
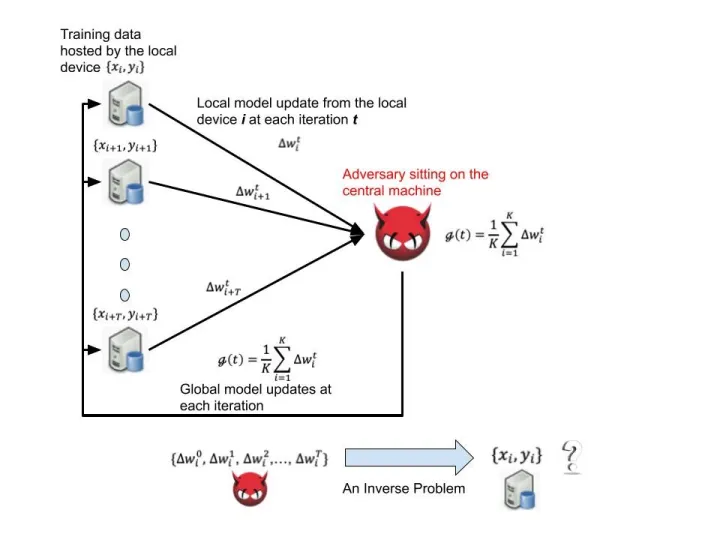
First of all, leakage of data privacy still persists as a great threat to Federated Learning when the central machine is compromised by an adversary. The risk of privacy leakage pertains to the architectural design of Federated Learning. On the central machine, the adversary knows the structure of the trained machine learning model and has a comprehensive view into how the model parameters are updated sequentially on any users' device. These observations can be used to infer reversely the statistical profiles of local data instances hosted by the users [3] or similarities between data instances hosted by different local users. This reverse engineering process can be mathematically defined as a well-known inverse problem [4], which aims to infer from a set of observations the causal factors that produced them.
It can easily be solved by the adversary with the aid of rich off-the-shelf optimization tools. For example, for federated learning of users' preference prediction model in an on-line purchasing recommendation system, if two users A and B submit similar local model updates consistently, this observation will give a strong signal to the adversary that the two users are likely to share the same preferences or habits of purchasing even though the original user preference records are not disclosed.
Norton Lab’s recent research unveils the risk of privacy leakage in Federated Learning as a model inversion adversarial attack, as demonstrated in Figure.2. The detailed information about the trained model is a white box to the adversarial attacker that compromise the central machine, which makes the whole learning system vulnerable to the adversarial privacy leakage threat.
Secondly, the quality of machine learning models trained by Federated Learning is vulnerable to diverse types of data corruption of local data sets hosted by customers' devices. Data corruption can be caused by random sensor noise or unpredictable failure of the distributed devices. It can be also the consequence of intentional data manipulation. For example, users can change their privacy policies to hide privacy-related attributes, or intentionally poison the hosted training data instances, which results in incomplete and noisy training data. Quality deterioration of training data will in turn make the behavior of a trained machine learning model greatly biased from what it should be. Requiring customers to verify data quality would be expensive; thus unrealistic for customers, even if they are willing to conduct data cleaning themselves. Our research work published on IJCNN 2019 [5] demonstrated the threat of contaminated local data sets to Federated Learning systems. In the study, we show that customers / device owners can arbitrarily bias the trained model's output by poisoning the data instances or even select a subset of the hosted data instances for training. Previously, there were research efforts [6,7] proposed to improve robustness of Federated Learning against byzantine device failures. Byzantine devices send the central machine model updates that significantly differ to the ones from the normal devices.
However, these works assume that Byzantine failure occurs occasionally only over a very tiny fraction of the users' devices. They can't handle the case where contamination of local data sets is more popularly witnessed, e.g. most of the devices host incomplete and / or noisy data instances and provide biased model updates. In our work published on AAAI 2020 [8], we discussed how to address this challenging situation and proposed the first defensive mechanism against the issue of low signal-to-noise ratio.
References:
- “Federated Optimization: Distributed Optimization Beyond the Datacenter,” Jakub Konecny, H. Brendan McMahan, Daniel Ramage, Nov. 11, 2015. https://arxiv.org/abs/1511.03575
-
“Tutorial: Federated Learning for Image Classification,” Tensorflow community page, Jan.31, 2020. https://bit.ly/396SQ52
- “Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures,” Matt Fredrikson, Somesh Jha, and Thomas Ristenpart, In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security (CCS ’15), Oct.12, 2015.
- “Inverse Problem Theory and Methods for Model Parameter Estimation,” Albert Tarantola, Institute de Physique du Globe de Paris, Universite de Paris 6, Jan.1, 2005, doi:10.1137/1.9780898717921.fm
- “Collaborative and Privacy-Preserving Machine Teaching via Consensus Optimization,” Yufei Han, Yuzhe Ma, Christopher Gates, Kevin Roundy and Yun Shen, In Proceedings of International Joint Conference on Neural Networks (IJCNN), July.14, 2019.
- “Machine learning with adversaries: Byzantine tolerant gradient descent,” Peva Blanchard, El Mahdi El Mhamdi, Richard Guerraoui and Julien Stainer, In Proceedings of NeurIPS 2017, Dec.4, 2017.
- “Draco: Byzantine-resilient distributed training via redundant gradients,“ Lingjiao Chen, Hongyi Wang, Zachary Charles and Dimitris Papailiopoulos., In Proceedings of International Conference on Machine Learning (ICML) 2018, July.10, 2018.
- “Robust Federated Learning via Collaborative Machine Teaching,“ Yufei Han and Xiangliang Zhang, In Proceedings of Association for the Advancement of Artificial Intelligence Conference (AAAI) 2020, Feb.9, 2020.





We encourage you to share your thoughts on your favorite social platform.