


Do Not Track My Face: A Call to Give People Autonomy Over Their Online Images
The Ethical Dilemmas of Facial Recognition and What to Do About It
This article was originally published by VentureBeat on July 5, 2020.
Facial recognition systems are a powerful AI innovation that perfectly showcase The First Law of Technology: “technology is neither good nor bad, nor is it neutral.” On one hand, law-enforcement agencies claim that facial recognition helps to effectively fight crime and identify suspects. On the other hand, civil rights groups such as the American Civil Liberties Union have long maintained that unchecked facial recognition capability in the hands of law-enforcement agencies enables mass surveillance and presents a unique threat to privacy. Research has also shown that even mature facial recognition systems have significant racial and gender biases; that is, they tend to perform poorly when identifying women and people of color (1). In 2018, a researcher at MIT showed many top image classifiers misclassify lighter-skinned male faces with error rates of 0.8%, but misclassify darker-skinned females with error rates as high as 34.7%. More recently, the ACLU of Michigan filed a complaint in what is believed to be the first known case in the United States of a wrongful arrest because of a false facial recognition match. These biases can make facial recognition technology particularly harmful in the context of law-enforcement.
One example that has received attention recently is “Depixelizer.”
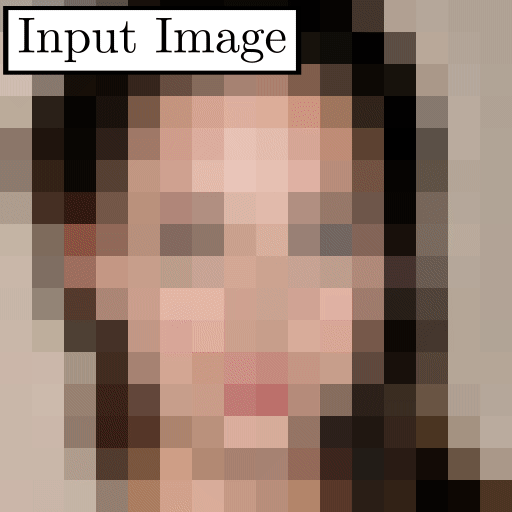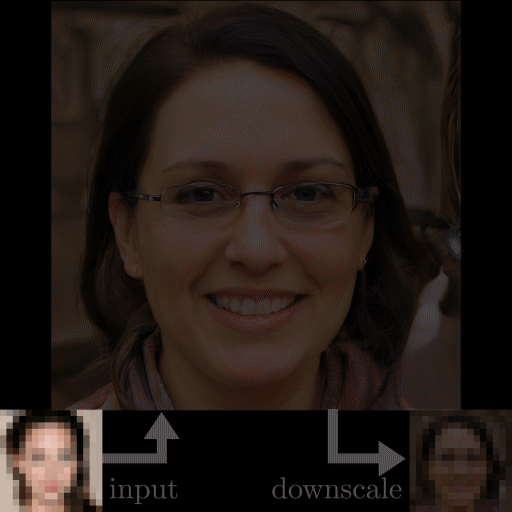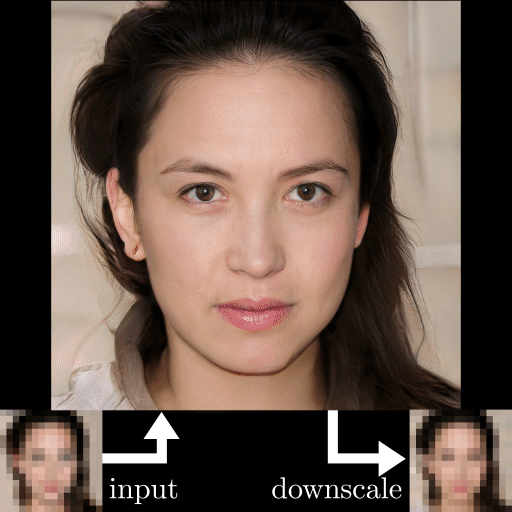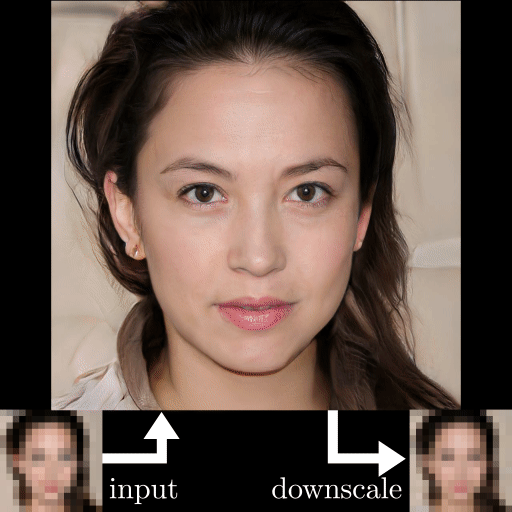
The project uses a powerful AI technique called a Generative Adversarial Network (GAN) to reconstruct blurred or pixelated images; however, machine learning researchers on Twitter found that when Depixelizer is given pixelated images of non-white faces, it reconstructs those faces to look white (2). For example, researchers found it reconstructed former President Barack Obama as a white man and Representative Alexandria Ocasio-Cortez as a white woman.

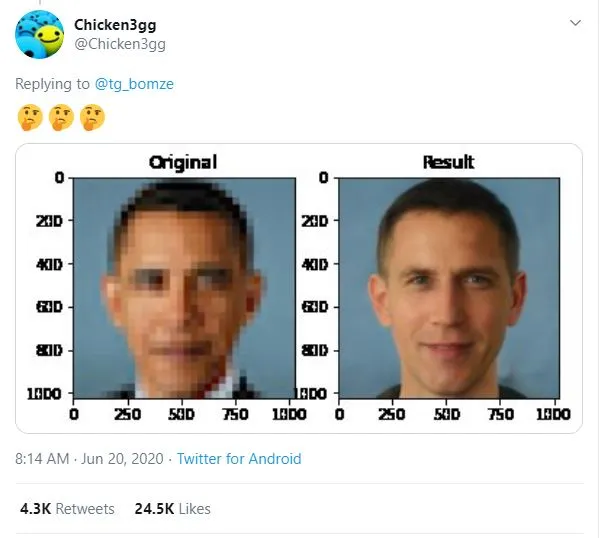
While the creator of the project probably didn't intend to achieve this outcome, it likely occurred because the model was trained on a skewed dataset that lacked diversity of images, or perhaps for other reasons specific to GANs (3). Whatever the cause, this case illustrates how tricky it can be to create an accurate, unbiased facial recognition classifier without specifically trying.
Currently, there are three main ways to safeguard the public interest from abusive use of facial recognition systems.
First, at a legal level, governments can implement legislation to regulate how facial recognition technology is used. Currently, there is no US federal law or regulation regarding the use of facial recognition by law enforcement. Many local governments are passing laws that either completely ban or heavily regulate the use of facial recognition systems by law enforcement, however, this progress is slow and may result in a patchwork of differing regulations.
Second, at a corporate level, companies can take a stand. Tech giants are currently evaluating the implications of their facial recognition technology. In response to the recent momentum of the Black Lives Matter movement, IBM has stopped development of new facial recognition technology, and Amazon and Microsoft have temporarily paused their collaborations with law enforcement agencies. However, facial recognition is not a domain limited to large tech firms anymore. Many facial recognition systems are available in the open-source domains and a number of smaller tech startups are eager to fill any gap in the market. For now, newly-enacted privacy laws like the California Consumer Privacy Act (CCPA) do not appear to provide adequate defense against such companies. It remains to be seen whether future interpretations of CCPA (and other new state laws) will ramp up legal protections against questionable collection and use of such facial data.
Lastly, people at an individual level can attempt to take matters into their own hands and take steps to evade or confuse video surveillance systems. A number of accessories, including glasses, makeup, and t-shirts are being created and marketed as defenses against facial recognition software. Some of these accessories, however, make the person wearing them more conspicuous. They may also not be reliable or practical. Even if they worked perfectly, it is not possible for people to have them on constantly, and law-enforcement officers can still ask individuals to remove them.
What is needed is a solution that allows people to block AI from acting on their own faces. Since privacy-encroaching facial recognition companies rely on social media platforms to scrape and collect user facial data, we envision adding a "DO NOT TRACK ME" (DNT-ME) flag to images uploaded to social networking and image-hosting platforms. When platforms see an image uploaded with this flag, they respect it by adding adversarial perturbations to the image before making it available to the public for download or scraping.
Facial recognition, like many AI systems, is vulnerable to small-but-targeted perturbations which, when added to an image, force a misclassification. Adding adversarial perturbations to facial recognition systems can stop them from linking two different images of the same person (4). Unlike physical accessories, these digital perturbations are nearly invisible to the human eye and maintain an image’s original visual appearance.
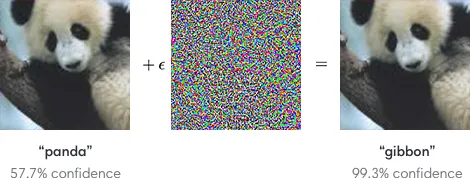
This approach of DO NOT TRACK ME for images is analogous to the DO NOT TRACK (DNT) approach in the context of web-browsing, which relies on websites to honor requests. Much like browser DNT, the success and effectiveness of this measure would rely on the willingness of participating platforms to endorse and implement the method – thus demonstrating their commitment to protecting user privacy. DO NOT TRACK ME would achieve the following:
Prevent abuse: Some facial recognition companies scrape social networks in order to collect large quantities of facial data, link them to individuals, and provide unvetted tracking services to law enforcement. Social networking platforms that adopt DNT-ME will be able to block such companies from abusing the platform and defend user privacy.
Integrate seamlessly: Platforms that adopt DNT-ME will still receive clean user images for their own AI-related tasks. Given the special properties of adversarial perturbations, they will not be noticeable to users and will not affect user experience of the platform negatively.
Encourage long-term adoption: In theory, users could introduce their own adversarial perturbations rather than relying on social networking platforms to do it for them. However, perturbations created in a “black-box” manner are noticeable and are likely to break the functionality of the image for the platform itself. In the long run, a black-box approach is likely to either be dropped by the user or antagonize the platforms. DNT-ME adoption by social networking platforms makes it easier to create perturbations that serve both the user and the platform.
Set precedent for other use cases: As has been the case with other privacy abuses, inaction by tech firms to contain abuses on their platforms has led to strong, and perhaps over-reaching, government regulation. Recently, many tech companies have taken proactive steps to prevent their platforms from being used for mass-surveillance. For example, Signal recently added a filter to blur any face shared using its messaging platform, and Zoom now provides end-to-end encryption on video calls. We believe DNT-ME presents another opportunity for tech companies to ensure the technology they develop respects user choice and is not used to harm people.
It’s important to note, however, that although DNT-ME would be a great start, it only addresses part of the problem. While independent researchers can audit facial recognition systems developed by companies, there is no mechanism for publicly auditing systems developed within the government. This is concerning considering these systems are used in such important cases as immigration, customs enforcement, court and bail systems, and law enforcement. It is therefore absolutely vital that mechanisms be put in place to allow outside researchers to check these systems for racial and gender bias, as well as other problems that have yet to be discovered.
It is the tech community’s responsibility to avoid harm through technology, but we should also actively create systems that repair harm caused by technology. We should be thinking outside the box about ways we can improve user privacy and security, and meet today’s challenges.
Footnotes
(1) While some adversarial perturbations are model-dependent, recent work has shown that many perturbations are transferable between models because their decision boundaries are quite similar. For example: https://www.usenix.org/system/files/sec19-demontis.pdf
(2) Depixelizer is based on the PULSE paper available here: https://arxiv.org/abs/2003.03808
(3) Mode-collapse is another possible explanation. See this article for an explanation: https://developers.google.com/machine-learning/gan/problems
(4) While tech companies have tried to address the racial problems in their models, more problems are constantly being discovered. Some examples: https://www.ft.com/content/7d3e0d6a-87a0-11e9-a028-86cea8523dc2
Copyright © 2020 NortonLifeLock Inc. All rights reserved. NortonLifeLock, the NortonLifeLock Logo, the Checkmark Logo, Norton, LifeLock, and the LockMan Logo are trademarks or registered trademarks of NortonLifeLock Inc. or its affiliates in the United States and other countries. Other names may be trademarks of their respective owners.






We encourage you to share your thoughts on your favorite social platform.