

Navigating the Online Tracking Maze: Journey to the Center of the Cookie Ecosystem
Consequences of Cookies for Consumers
Web user tracking has been at the center of public attention, both for the key role it plays in the web advertising industry, including big scandals such as Cambridge Analytica and for being the target of recent major legislative efforts. In recent research Norton Labs conducted, which will be presented at IEEE Symposium on Security and Privacy (S&P), we looked under the hood of web pages and captured the entire life cycle of cookies, from their creation to all the operations they were later involved in. We uncovered the intricate network of relationships between actors that take part in tracking users online (such as those demonstrated in the example figure below).
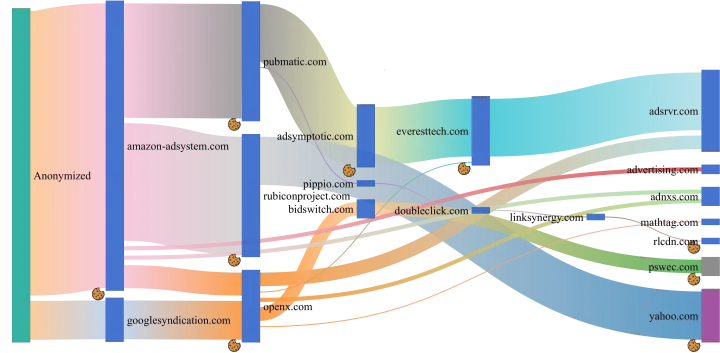
Our analysis allows us to paint a highly detailed picture of the cookie ecosystem, discovering an intricate network of connections between players that reciprocally exchange information and include each other’s content in web pages – sometimes without even the web page owners’ knowledge. We discovered that, in most webpages, tracking cookies are set and shared by organizations at the end of complex chains that involve several middlemen.
Following the Trail of Cookie Crumbs
In order to investigate cookie lifecycles in-depth, we introduced the concepts of cookie trees, creation and sharing chains, which enabled us to capture the dependencies and relationships between entities that act as both endpoints and middlemen in the cookie ecosystem. We also defined the concept of cookie ghostwriting, a new tracking approach, which relates to cookies that are set for a party (e.g., the website the user is visiting), but are actually created by a different entity (e.g., a script loaded from an advertiser). This technique is present in 43% of the websites analyzed, has been implemented by many important tracking actors, and allows them to hide from current detection systems.
Let’s look at an example found in a famous image and video hosting service. Its homepage included a JavaScript file (s.js) from siftscience.com (a domain belonging to a company that provides digital trust services). The script used a popular fingerprinting library (fingerprintjs2) to create a first-party cookie named __ssid. According to our definitions, this is a “ghosted cookie” (i.e., the result of cookie ghostwriting), as it was associated to the image and video hosting service domain, but it was in fact created and controlled by a different entity. Moreover, the same script from siftscience.com then took the newly created cookie and sent it to hexagon-analytics.com (which provides analytics services for news and trending topics). All this identifier creation and sharing situations were undetectable by previous analysis approaches. Furthermore, the same information flow involving the exact same actors appears in several other popular websites.
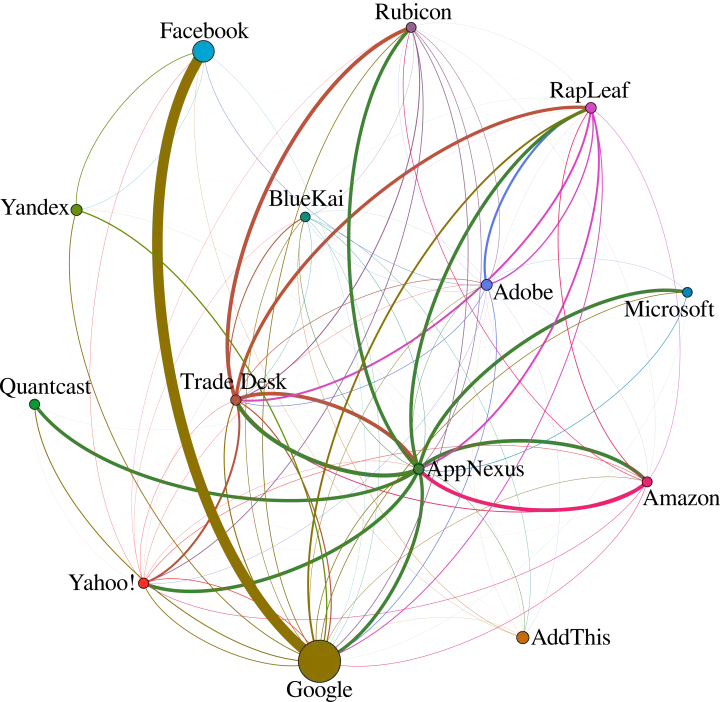
We performed a large-scale measurement study, in which we collected fine-grained details of 138M cookies, from crawling 6.2M web pages.
We attributed and defined a set of roles in the cookie ecosystem, related to cookie creation and sharing. We saw that organizations can and do follow different patterns (as shown in the image), including behaviors that previous studies could not uncover: for example, many cookie ghostwriters sent cookies they created to themselves, which makes them able to perform cross-site tracking even for users that deleted certain or all third-party cookies in their browsers. While some organizations concentrated the flow of information on themselves, others behaved as dispatchers, allowing other organizations to perform tracking on the pages that include their content.
Our results clearly indicate that our approach uncovers significantly more organizations and relationships. This demonstrates the added value of performing a deeper investigation of the cookie creation and sharing events. In particular, the analysis of cookie trees enabled us to identify as many as 171,140 organizations that are involved in the creation and sharing of cookies and 809,179 relationships, improving the state of the art by 254% and 435%, respectively.
Implications for the Current Web Panorama and Consumers
From the point of view of website owners and developers, the sheer number of actors involved in each page makes it difficult to guarantee that user privacy is respected. Recent data protection legislations require strict control on user identifiable information, but due to this intricate structure, ensuring compliance with current regulations may be very difficult without advanced methods to inspect how information flows. Moreover, we have unfortunately encountered content from potentially dangerous sources associated to cookie creation and sharing. On the one hand, we can envision that enforcement of current and upcoming privacy jurisprudence will keep limiting the amount of unwanted data sharing between trackers; on the other hand, we believe that finer-grained approaches, such as the one we developed, will help in detecting actors who try to skirt the rules.
From a preventive point of view, there are various aspects to consider. Existing blocking solutions use precalculated lists in order to block tracking, and they successfully include most of the larger actors of the cookie ecosystem. However, our study shows that a large number of smaller players are not present in those lists, and that these actors often play important roles in creation and sharing chains. Cookie trees and information flows offer a systematic way to better understand each actor, together with its role, in the tracker lists. Basic cookie analysis may erroneously underestimate or misclassify many actors, such as those that create ghosted cookies or work as dispatchers for other players in the ecosystem. By allowing these tools to identify and stop the tracking process from its initial stage, our approach can largely improve current efficiency while avoiding anti-blocking strategies that can lead to other privacy violations. Technology and innovation prototypes developed by NortonLifeLock Labs can help consumers stay safe and protected from such online tracking. Stay tuned!
No one can prevent all identity theft.
† LifeLock does not monitor all transactions at all businesses.
* Reimbursement and Expense Compensation, under the LifeLock Million Dollar Protection™ Package does not apply to identity theft loss resulting, directly or indirectly, from phishing or scams.
Editorial note: Our articles provide educational information for you. NortonLifeLock offerings may not cover or protect against every type of crime, fraud, or threat we write about. Our goal is to increase awareness about cyber safety. Please review complete Terms during enrollment or setup. Remember that no one can prevent all identity theft or cybercrime, and that LifeLock does not monitor all transactions at all businesses.
Copyright © 2020 NortonLifeLock Inc. All rights reserved. NortonLifeLock, the NortonLifeLock Logo, the Checkmark Logo, Norton, LifeLock, and the LockMan Logo are trademarks or registered trademarks of NortonLifeLock Inc. or its affiliates in the United States and other countries. Other names may be trademarks of their respective owners.





We encourage you to share your thoughts on your favorite social platform.