


The Tangle of Service Dependencies: Has the Internet Become Brittle?
Learn about potential Internet infrastructure hazards
In October 2016, Dyn -- an important Internet service provider (ISP) -- fell victim to a large attack which made its Domain Name System (DNS--the service that associates names like www.nortonlifelock.com to numeric addresses like 23.43.28.184) unavailable for several hours. Many websites, including Twitter, Spotify, and Reddit, were affected in the aftermath.
This event was followed by a series of similar incidents where the services given by large providers go offline, carrying a large chunk of the Internet with them; ironically, also some services allowing verifying whether other services are active went down as well. Large attacks are not the only problem here: a frequent cause of these events is misconfiguration.
The Internet was designed to be fault-tolerant, distributed and so resilient that it should withstand nuclear attacks. Then why can a small mistake break so much of it?
Services like DNS, WWW, and email are designed to be highly distributed, isolate failures and facilitate recovery. In this setup, engineers aren’t the problem. The problem goes back to the underlying economics: keeping services reliable and performing is both difficult and expensive. For decades, companies have hosted email and web servers on ISPs' premises. Rather than hosting services in-house, ISPs were able to leverage economies of scale and expertise to provide comparatively inexpensive but quality services. The downside is that ISP-wide failures are possible. Only when ISPs are relatively small can failures be contained.
Cloud services facilitated the shifting of infrastructure and services to third parties; nowadays, smaller players struggle against fierce competition. The sophistication of survivors may make failures less likely, but when they do happen—by mistake or through malice—the results can be catastrophic, impacting large chunks of the Internet.
Mapping Internet Service Dependencies
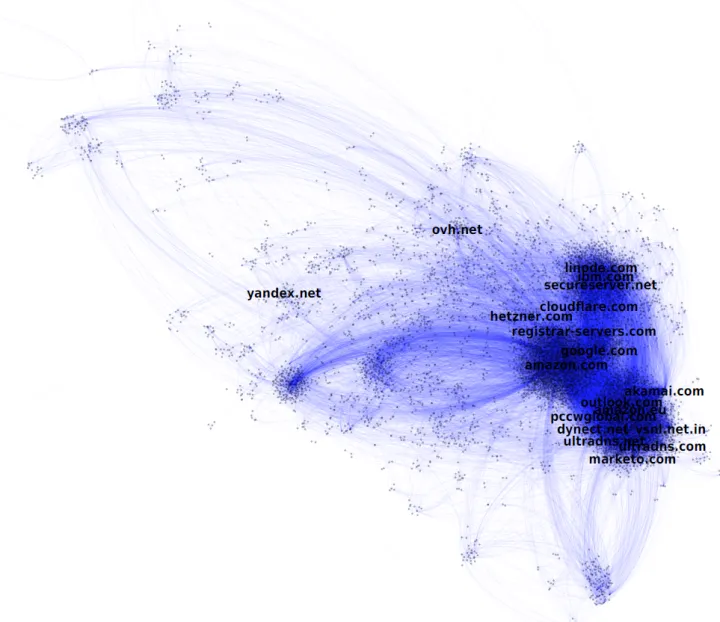
With colleagues at Norton Labs, we studied the complex web of relationships between companies in order to identify who depends on which third party services. Not all relations are public and there is no easy way to obtain all of them. However, we discovered that the DNS, one of the services we examined, contains critical information which supports observing several associations.
For example, when a user queries the location of www.exampledomain.com, the DNS returns an answer meaning "lookup this other name: server123.exampleprovider.com." Hence, we understand that exampledomain.com's web server is hosted at exampleprovider.com. If the DNS query is answered with an IP address (the numeric addresses used to route Internet traffic), we can do a reverse DNS query that will map an address like "104.85.45.51" to server.exampleprovider.com. We mined these relationships in more than 2.5 trillion DNS queries carried out by real users, including some additional ones we performed--all details are available in the paper we authored for publication at the ACSAC 2017 conference.
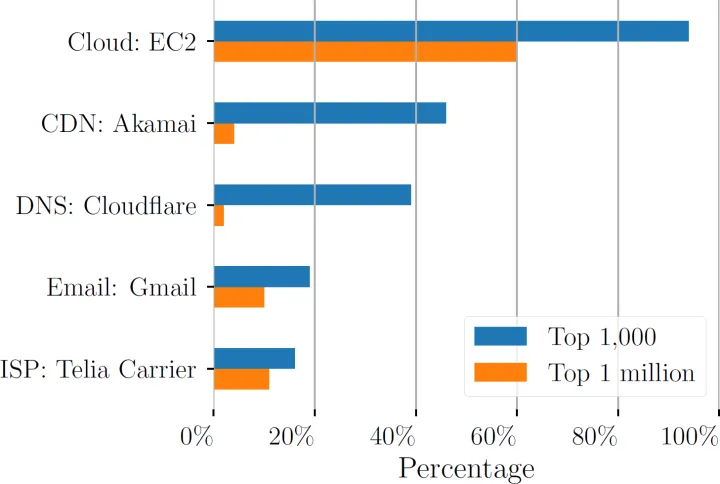
The Internet is becoming less decentralized. Large players--such as Akamai, Amazon, Cloudflare, Dyn, Go Daddy and Google--show up everywhere; and with time, big providers tend to become even bigger.
When introducing this post, the described failures were still contained compared to the worst-case scenarios, impacting for a limited time only a few of the services and customers handled by the biggest players. We compared our results with a list of affected services in the Dyn attack: only half of them were using a Dyn DNS server. What about the others? We think the other half was relying on Dyn indirectly by depending on services that were Dyn's customers. In other words, these were cascading failures: an unavailable service makes others unavailable, which may impact others, consequently enabling a scary domino effect.
Can We Contain the Contagion?
This domino effect closely resembles epidemics: when one service becomes unavailable, it has some probability of "infecting" its neighbors (i.e. the services depending on it) which makes them unavailable as well. Epidemic modeling is the study of how contagion probability predicts whether epidemics will die out quickly or become widespread in the population. For example, these studies compute which percentage of vaccinated population ensures herd immunity. This works in human contact networks, where the number of people a person can infect is limited. However, when the network is of the scale-free kind (e.g. few “hubs” are connected to a large fraction of the network), lowering contagion probability is not enough. Epidemics will not die out and will affect a significant part of the whole population. Unfortunately, the service dependency network we discovered is scale-free. Because of the dependency on a few central actors, we face the danger of massive Internet failures.
Takeaways
The Internet became less decentralized and less resilient than one could assume as more and more services get delegated to a few, very large providers.
Delegation is often a smart decision--specialized providers often offer great services at reasonable prices. However, the flip side of this is that the Internet, as a whole, risks huge disruptions.
Considering the countermeasures, we believe the key is redundancy. That means having backup solutions available if a provider fails, all the while assessing the risk of chain failures. To ensure reliability when everybody else is down, one can turn to smaller trusted providers that will still be up and running even when catastrophic failures are taking down the bigger guys.
We believe that the danger of massive Internet failures shouldn't be ignored; and we hope that, as our lives depend more and more on the Internet, our work can ignite discussion on ways to monitor and minimize the risks.
Authors: Matteo Dell’Amico, Leyla Bilge, Petros Efstathopoulos, Pierre-Antoine Vervier, K. Ashwin Kumar






We encourage you to share your thoughts on your favorite social platform.